
En la carrera de hoy para acelerar el tiempo de carga del sitio web, cada milisegundo es importante. El equipo de Kinsta probó y estudió el impacto de la velocidad del sitio web en las ventas, las conversiones, la experiencia del usuario y el compromiso del usuario.
Pero hay una advertencia. Aunque la optimización en el sitio web es importante para mejorar la velocidad, no es el único aspecto en el que debemos fijarnos. El hardware y la infraestructura de red que soportan nuestro sitio web y lo conectan con nuestros visitantes también importan. Y mucho.
Hoy discutiremos por qué Google está invirtiendo mucho dinero en su infraestructura de red, y algunas de las diferencias en la red de nivel premium y la red de nivel estándar de Google Cloud Platform.
Ancho de Banda y Latencia (Criterios Clave para el Rendimiento de la Infraestructura de Alojamiento)
Antes de entrar en detalles sobre las redes de Google Cloud, es importante entender primero los dos conceptos siguientes: ancho de banda y latencia.
El ancho de banda es la capacidad de rendimiento de la red, medida en Mbps; mientras que la latencia es el tiempo de retraso o la suma de todos los retrasos que los diferentes enrutadores a lo largo del camino añaden a nuestras solicitudes y respuestas web.
En términos figurados, el ancho de banda o el caudal se puede representar como la capacidad de una manguera de agua para permitir el paso de un cierto volumen de agua por segundo. La latencia se puede comparar con el tiempo de espera desde el momento en que se abre la tubería de agua hasta que empieza a salir a chorros.
Debido a la pequeña sobrecarga en el establecimiento de la conexión entre diferentes routers, cada «salto» a lo largo del camino añade una pequeña cantidad de latencia a las solicitudes y respuestas finales.
Por lo tanto, cuanto más lejos estén el visitante y el servidor donde está alojado el sitio web, mayor será la latencia. Además, cuanto más fragmentada esté la red, mayor será la latencia.
Podemos imaginárnoslo usando una herramienta llamada Traceroute, o tracert en windows. En las siguientes capturas de pantalla, lo utilizamos para inspeccionar los retrasos en el enrutamiento de dos solicitudes, realizadas desde Europa. Específicamente:
uno a weibo.com:

y otro a bbc.co.uk:

Como esperábamos, el número de saltos a la página web en China es casi dos veces mayor que el de la europea. Así que es la latencia añadida en comparación con una petición a un sitio web alojado en el Reino Unido.
Las tres columnas que muestra tracert representan tres viajes de ida y vuelta (RTT). Cada fila representa diferentes enrutadores o saltos a lo largo del camino. A menudo tienen URLs que nos ayudan a determinar dónde se encuentra ese enrutador específico.
El tiempo de ida y vuelta a los routers en China / Hong Kong es de casi un tercio de segundo.
Usamos pingdom herramientas para cargar un sitio web alojado en Londres desde la ubicación de Pingdom en Australia, para tratar de establecer la parte que la red tiene en los tiempos totales de carga de un sitio web.

Estos son los datos de un pequeño archivo CSS cargado en este escenario de prueba. La parte de Connect es la que tiene el mayor porcentaje de carga de este recurso, seguida de SSL y Wait. Todo el tiempo hasta, e incluyendo el tiempo de espera, también se conoce como tiempo hasta el primer byte (TTFB), que incluye la latencia de la red.
Cuando los Proveedores de Servicios de Internet anuncian la velocidad de la conexión a Internet, normalmente lo hacen en su ancho de banda (el «ancho de la manguera», ¿recuerda?), lo que no es realmente un medida de velocidad. Aumentar el ancho de la tubería puede aumentar la velocidad del sitio web sólo hasta cierto punto. Es más útil cuando necesitamos una gran cantidad de datos enviados por segundo, como cuando transmitimos contenido de vídeo de alta definición. Pero para los usuarios que pueden estar jugando juegos multijugador en tiempo real en línea, la latencia importará mucho más.
Mike Belshe, uno de los coautores de la especificación HTTP/2 y el protocolo SPDY, hizo un análisis del impacto del aumento del ancho de banda en la velocidad de carga del sitio web frente al efecto de la disminución de la latencia en la velocidad de carga del sitio web.
Aquí están los hallazgos de Belshe curados en un bonito cuadro:

Debe quedar claro que mejorar la velocidad del sitio web aumentando el ancho de banda no es la forma más efectiva de alcanzar un mejor rendimiento. Por otro lado, al reducir el RTT (tiempo de ida y vuelta) o la latencia, podemos ver mejoras consistentes de la tiempo de carga de la página.
Redes vs Internet Peering vs Tránsito
Para entender un poco mejor nuestro tema, necesitamos explicar los fundamentos de la topología de Internet. En su esencia, Internet global consiste en múltiples redes globales, regionales y locales.
A partir de 2018, hay más de 60.000 AS (Sistemas Autónomos). Estas redes pertenecen a gobiernos, universidades, ISPs.
Entre ellas, distinguimos las redes de Nivel 1, Nivel 2 y Nivel 3. Estos niveles representan la independencia de cada red en Internet en su conjunto.
- Las redes Tier 1 son independientes, en el sentido de que no tienen que pagar para conectarse a cualquier otro punto de Internet.
- Las redes de nivel 2 tienen acuerdos igualitarios con otros ISP, pero también pagan por el tránsito.
- Las redes de nivel 3, el nivel más bajo, se conectan al resto de Internet comprando tránsito de niveles más altos. Son prácticamente como los consumidores que tienen que pagar para acceder a Internet.
La relación de interconexión significa que dos redes intercambian tráfico en igualdad de condiciones, de modo que ninguna de ellas paga a la otra por el tránsito y devuelve el mismo gratuitamente.
El principal beneficio de los peering es una latencia drásticamente menor.

En la imagen de arriba, vemos un escenario clásico, donde la petición web pasa a través de la red jerárquica de ISPs en los niveles 1, 2 y 3 para recuperar un sitio web alojado en un directorio centro de datos en una ubicación remota.
Las flechas representan el recorrido de la solicitud web. Las flechas punteadas representan las conexiones de tránsito, y las flechas de línea completa representan las conexiones igualitarias.
Una vez que se llega al proveedor de nivel 1, su relación con otro proveedor en el mismo nivel es una relación de pares. Las redes de nivel 1 se conectan con otras y transmiten sus peticiones exclusivamente a través de socios igualitarios. Pueden llegar a todas las demás redes en Internet sin tener que pagar por el tránsito.
También podemos ver un escenario alternativo, donde dos proveedores de nivel 2 tienen un acuerdo igualitario, designado con color turquesa. El número de saltos en este escenario es menor y el sitio web tardará mucho menos en cargarse.
Border Gateway Protocol
BGP es un protocolo del que rara vez se habla, excepto en contextos muy técnicos. Sin embargo, este protocolo se encuentra en el centro mismo de Internet tal y como lo conocemos hoy en día. Es fundamental para nuestra capacidad de acceder a casi todo en Internet y es uno de los enlaces vulnerables en la pila de protocolos de Internet.
El protocolo Border Gateway está definido en los IETFs Solicitud de Comentarios #4271 de 2006 y desde entonces ha tenido varias actualizaciones. Como dice el RFC:
«La función principal de un sistema de habla BGP es intercambiar información de accesibilidad de red con otros sistemas BGP.»
En pocas palabras, BGP es un protocolo responsable de decidir la ruta exacta de una solicitud de red, a través de cientos y miles de posibles nodos a su destino.

Podemos imaginar cada nodo como un Sistema Autónomo o una red que consistiría en múltiples nodos o enrutadores, servidores y sistemas conectados a él.
En el protocolo BGP, no hay un algoritmo de auto-descubrimiento (un mecanismo o protocolo por el cual cada nodo recién conectado puede descubrir nodos adyacentes a través de los cuales conectarse), en cambio, cada par BGP tiene que tener sus pares especificados manualmente. En cuanto al algoritmo de la ruta, para citar a un experto de Cisco:
«BGP no tiene una métrica simple para decidir qué camino es el mejor. En su lugar, anuncia un extenso conjunto de atributos con cada ruta y utiliza una complejo algoritmo que consiste en hasta 13 pasos para decidir qué camino es el mejor».
Los sistemas autónomos transmiten los datos de enrutamiento a sus pares, sin embargo, no hay reglas estrictas que se puedan aplicar con respecto a la selección del camino. BGP es un sistema basado implícitamente en la confianza y este puede ser uno de los mayores defectos de seguridad de la Internet actual. El robo en 2018, cuando el tráfico de MyEtherWallet.com fue secuestrado, y más de 200 Ether fueron robados (valorados en $152,000) expuso esta vulnerabilidad.
En realidad, esta debilidad de BGP hace que varias redes (AS) emitan datos BGP con otros intereses en mente además de la eficiencia y el rendimiento de velocidad para los usuarios finales. Estos pueden ser intereses comerciales, como el tránsito pagado, o incluso consideraciones políticas o de seguridad.
Desarrollo del Cloud Computing, la CDN y el Edge Market
Debido a las crecientes necesidades del mercado de TI, desde la industria de la web, los juegos en línea, hasta el Internet de los objetos y otros, el espacio de mercado para los proveedores de servicios y productos que resuelven el problema de la latencia se hizo evidente.
Año tras año vemos más productos basados en la nube que almacenan en caché recursos estáticos cerca de los visitantes (redes de entrega de contenidos) o acercan la informática real a los usuarios finales. Uno de estos productos es Cloudflare’s Workers, que ejecuta Código V8 compatible con el motor javascript en la red de nodos de borde de Cloudflare. Esto significa que incluso el código de WebAssembly o GO puede ejecutarse muy cerca del visitante.
[email protected] by Amazon es otro ejemplo de esta tendencia, así como la asociación entre Intel y Alibaba Cloud para ofrecer una plataforma informática de vanguardia conjunta destinada al mercado de la IO.
Otra que vale la pena mencionar es la red global de nodos de almacenamiento en caché de Google que sirve como CDN y como red de almacenamiento y entrega de vídeo para su filial. YouTube.
Para ilustrar lo refinado y avanzado que se ha vuelto el sector de la nube, y lo mucho que ha conseguido reducir la latencia de red para usuarios finales, echemos un vistazo a GaaS.
GaaS es la abreviatura de Gaming as a Service. Es una oferta en nube que ofrece a los usuarios la posibilidad de jugar a juegos alojados y ejecutados en la nube. Este artículo compara algunos productos prominentes en el nicho de GaaS.
Cualquiera que haya comprado alguna vez un televisor o un proyector de vídeo para jugar, o que haya pasado algún tiempo configurando Miracast u otra conexión de casting entre un televisor y otro dispositivo, sabrá lo crítico que es la latencia. Sin embargo, hay proveedores de GaaS que ahora ofrecen streaming de juegos con una resolución de 4k y una frecuencia de actualización de 60Hz….y los jugadores no tienen que invertir en hardware.
El drama de la reciente prohibición de Huawei por parte de los EE.UU. llamó la atención sobre el tema de las redes 5G y la urgente necesidad de un camino claro para mejorar la infraestructura de redes del mundo.
Los sensores que transmiten grandes cantidades de información en tiempo real, con una latencia mínima, para coordinar ciudades inteligentes, casas inteligentes y vehículos autónomos dependerán de redes densas de dispositivos de borde. La latencia es el techo actual para cosas como los coches de autoconducción, con diferentes sensores de información, datos LIDAR, el procesamiento de estos datos frente a los datos de otros vehículos.
Las redes de distribución de contenidos y los proveedores de Cloud Computing están a la vanguardia de esta carrera. Ya hemos hablado del protocolo QUIC / HTTP3 está siendo implementado por los líderes de la industria capaces de controlar el ciclo de solicitud-respuesta.
¿Cómo Resuelven los Proveedores de Cloud Computing el Problema de la Latencia?
AWS puede ser el mayor proveedor de cloud computing por cuota de mercado. En 2016, invirtieron en Hawaiki Transpacific Submarine Cable System con el objetivo de proporcionar un mayor ancho de banda y reducir la latencia entre Hawai, Australia y Nueva Zelanda, que era su principal objetivo primera inversión en infraestructura submarina. Se se puso en marcha en 2018.

En ese momento, Google ya estaba muy por delante de su competencia en la creación de redes troncales submarinas. Un año antes de la primera inversión de Amazon, ITWorld publicó un artículo titulado: «Los centros de datos de Google crecen demasiado rápido para las redes normales, por lo que construye los suyos propios».
De hecho, fue en 2005 cuando el periodista tecnológico Mark Stephens, alias Robert X Cringely escribió en su para PBS.org, comentando sobre la juerga de compras de Google en la revista fibra oscura (disposición pero infraestructura de fibra óptica no utilizada):
«Esto es más que otro Akamai o incluso un Akamai en esteroides. Se trata de una Akamai inteligente, termonuclear, dirigida dinámicamente, con un back-channel dedicado y hardware aplicación específica. Habrá Internet, y luego estará Internet de Google, superpuesta en la parte superior».

En 2010, en un artículo en zdnet.com, dice Tom Foremski:
«Google es una de esas empresas que poseen una gran parte de Internet», y continúa: «Google se ha centrado en construir la Internet privada más eficiente y de menor costo de operación. Esta infraestructura es clave para Google, y es clave para entender a Google».
En ese momento, el artículo de Cringley planteaba algunas preocupaciones sobre el intento de Google de hacerse con el control de Internet, pero las cosas se hicieron más claras cuando la empresa puso en marcha Google Fiber, el intento de Google de conquistar el mercado de los ISP en las ciudades más grandes de Estados Unidos. El proyecto se ha ralentizado desde entonces, tanto que TechRepublic publicó un informe post-mortem del proyecto en 2016, pero las inversiones en la infraestructura, ahora a escala mundial, no se ralentizó.
Google La última inversión, que se pondrá en marcha este año, es una columna vertebral que conecta Los Ángeles, en Estados Unidos, y Valparaíso, en Chile, con una sucursal para la futura conexión con Panamá.
«Internet se describe comúnmente como una nube. En realidad, es una serie de tubos húmedos y frágiles, y Google está a punto de poseer un alarmante número de ellos». — VentureBeat
¿Por qué está Invirtiendo Tanto Google en su Infraestructura de Red?

Todos sabemos que Google es el motor de búsqueda número uno, pero también:
- Posee la plataforma de vídeo más grande
- Es el mayor proveedor de correo electrónico (Gmail y Google Workspace)
- Gana bastante dinero con sus productos de computación en nube (tasa de ejecución anual de más de 8 mil millones de dólares)
Por eso necesita la menor latencia posible y el mayor ancho de banda posible. Google también quiere poseer la infraestructura actual, porque su «hambre insaciable» de más ancho de banda y latencia pone a Google, y a sus compañías de gran escala como Amazon o Microsoft, en una posición en la que necesitan encontrar soluciones de hardware y software completamente personalizadas.

Los puntos de presencia, o nodos PoP de borde, se encuentran en los bordes de la red de cable privada global de Google. Allí sirven como puntos de entrada y salida para el tráfico que conecta con los centros de datos de Google.
Moore’s Law es una observación de Gordon Moore, cofundador de Intel, que afirma que cada dos años, el número de transistores que podemos poner en un circuito integrado se duplicará. Durante décadas, esta expectativa fue cierta, pero ahora, la industria de la computación está a punto de poner a prueba la ley de Moore, tal vez firmando su fin en un futuro cercano. PARA TU INFORMACIÓN, El Consejero Delegado de NVIDIA proclamó la muerte de Moore a principios de año.
Entonces, ¿cómo se relaciona esto con la industria de la nube y con la infraestructura de red de Google?
En el evento Open Networking Foundation Connect Event de diciembre de 2018, la vicepresidenta de Google y TechLead for Networking, Amin Vahdat, admitió el final de la ley de Moore y explicó el enigma de la empresa:
«Nuestra demanda informática sigue creciendo a un ritmo asombroso. Necesitaremos aceleradores y una computación más ajustada. El tejido de la red va a jugar un papel crítico en la unión de esos dos».
Una forma en la que los proveedores de cloud computing pueden mantenerse al día con la creciente demanda de potencia de cálculo es la agrupación en clústeres. Clustering, para decirlo de forma sencilla, significa reunir varios ordenadores para trabajar en un solo problema, para ejecutar los procesos de una sola aplicación. Obviamente, una condición previa para beneficiarse de esta configuración es la baja latencia o la gran capacidad de la red.
Cuando Google comenzó a diseñar su propio hardware, en 2004, los proveedores de hardware de red pensaban en términos de cajas, y los routers y switches debían gestionarse de forma individual, a través de una línea de comandos. Hasta entonces, Google estaba comprando clusters de switches de proveedores como Cisco, gastando una fortuna por cada switch. Pero el equipo seguía sin poder seguir el ritmo de crecimiento.
Google necesitaba una arquitectura de red diferente. La demanda de la infraestructura de Google crecía exponencialmente (un de Google a partir de 2015 afirma que su capacidad de red aumentó 100 veces en diez años) y que su crecimiento fue tan rápido que el costo de comprar el hardware existente también los impulsó a crear sus propias soluciones. Google comenzó a crear conmutadores personalizados a partir de chips de silicio de productos básicos, adoptando una topología de red diferente que era más modular.
Los ingenieros de Google comenzaron a construir sobre un viejo modelo de red telefónica llamado Clos Network, que reduce el número de puertos requeridos por switch:
Más información sobre este modelo como Conferencia de la Universidad de Harvard disponible en línea.
Para este nuevo hardware modular, el equipo de Google también tuvo que redefinir los protocolos existentes y construir un sistema operativo de red personalizado. El reto al que se enfrentaban era el de tomar un gran número de conmutadores y routers y hacerlos funcionar como si se tratara de un único sistema.
La pila de redes personalizadas, junto con la necesidad de protocolos redefinidos, llevó a Google a recurrir a Software Defined Networking (SDN). A continuación, Amin Vahdat, vicepresidente de Google, miembro del equipo de ingeniería y líder del equipo de infraestructuras de red, explicará a partir de 2015 todos los retos y las soluciones que se les ocurrieron:
Para los más curiosos, hay esta interesante entrada de blog que vale la pena leer.
Espresso
Espresso es el último pilar del SDN de Google. Permite a la red de Google ir más allá de las limitaciones de los routers físicos para aprender y coordinar el tráfico que entra y sale de los partners de Google.
Espresso permite a Google medir el rendimiento de las conexiones en tiempo real y basar la decisión en el mejor punto de presencia para un visitante específico a partir de datos en tiempo real. De esta manera, la red de Google puede responder dinámicamente a diferentes congestiones, ralentizaciones o interrupciones en sus socios peering / ISP.
Además, Espresso permite utilizar la potencia informática distribuida de Google para analizar todos los datos de la red de sus colegas. Todo el control y la lógica del enrutamiento ya no reside en los enrutadores individuales y en el protocolo Border Gateway, sino que se transfiere a la red informática de Google.
«Aprovechamos nuestra infraestructura de computación a gran escala y las señales de la propia aplicación para saber cómo se están comportando los flujos individuales, según lo determine la percepción de calidad del usuario final». — Espresso hace que Google Cloud sea más rápido, 2017
¿Qué Importancia Tiene esto para la Red en la Google Cloud?
Lo que hemos cubierto hasta ahora va a poner de relieve todos los problemas y desafíos (tanto basados en hardware como en software) por los que ha pasado Google para crear lo que probablemente sea la mejor red privada global disponible en la actualidad.
En cuanto a la cuota de mercado, Google Cloud Platform es el tercer proveedor mundial (tras AWS y de Azure de Microsoft).
Pero en términos de su infraestructura de red privada de primera calidad, deja a sus competidores muy atrás, tal y como muestran estos datos de BroadBand Now:

En 2014, GigaOM publicó un artículo comparando AWS y Google Cloud Platform, pero sólo una semana después, publicaron otro titulado: «Lo que me perdí en el debate Google vs. Amazon – fibra», donde reconocen que Google está años por delante en términos de infraestructura.
«Tener tuberías grandes y rápidas disponibles para su tráfico y el de sus clientes es un gran problema.» — Barb Darrow, GIGAOM
Las Redes Premium de Google frente a las Redes de Nivel Estándar

Google Cloud Platform ofrece dos niveles de red diferentes que difieren tanto en precio como en rendimiento.
Red de Niveles Premium de Google
Con la red de nivel superior de Google, los usuarios pueden aprovechar la red de fibra global, con puntos de presencia distribuidos globalmente. Todo el tráfico entrante (entrante) del cliente a los centros de datos de Google se enruta al punto de presencia más cercano, que se distribuye globalmente, y luego la solicitud se enruta al 100% a través de la red troncal privada de Google. Como mencionamos en un artículo anterior – eso puede significar un 30% más de latencia o un 50% más de ancho de banda.
En el camino de regreso, todos los datos enviados desde el centro de datos al visitante se enrutan utilizando Política de patatas frías. A diferencia de la Enrutamiento Hot Potato, utilizado en la red Standard Tier, donde el tráfico es, tan pronto como sea posible, entregado (o eliminado) a otros ISP-s, el enrutamiento Premium Tier significa que el tráfico de salida se mantiene el mayor tiempo posible en la propia fibra de Google, y se entrega a los pares o ISPs de tránsito tan cerca del visitante como sea posible.
Para decirlo en términos simples. Los paquetes de nivel Premium pasan más tiempo en la red de Google, con menos rebotes, y por lo tanto se desempeñan mejor (pero cuestan más).
Para los aficionados a la ciencia ficción entre nosotros, podría ser comparado con un agujero de gusano cósmico, que transfiere nuestro tráfico directamente a nuestro destino sin necesidad de desplazarse a través de Internet.
En Kinsta, utilizamos la Red de Nivel Premium de Google Cloud con todos nuestros planes de alojamiento. Esto minimiza la distancia y los saltos, lo que resulta en un transporte global más rápido y seguro de sus datos.
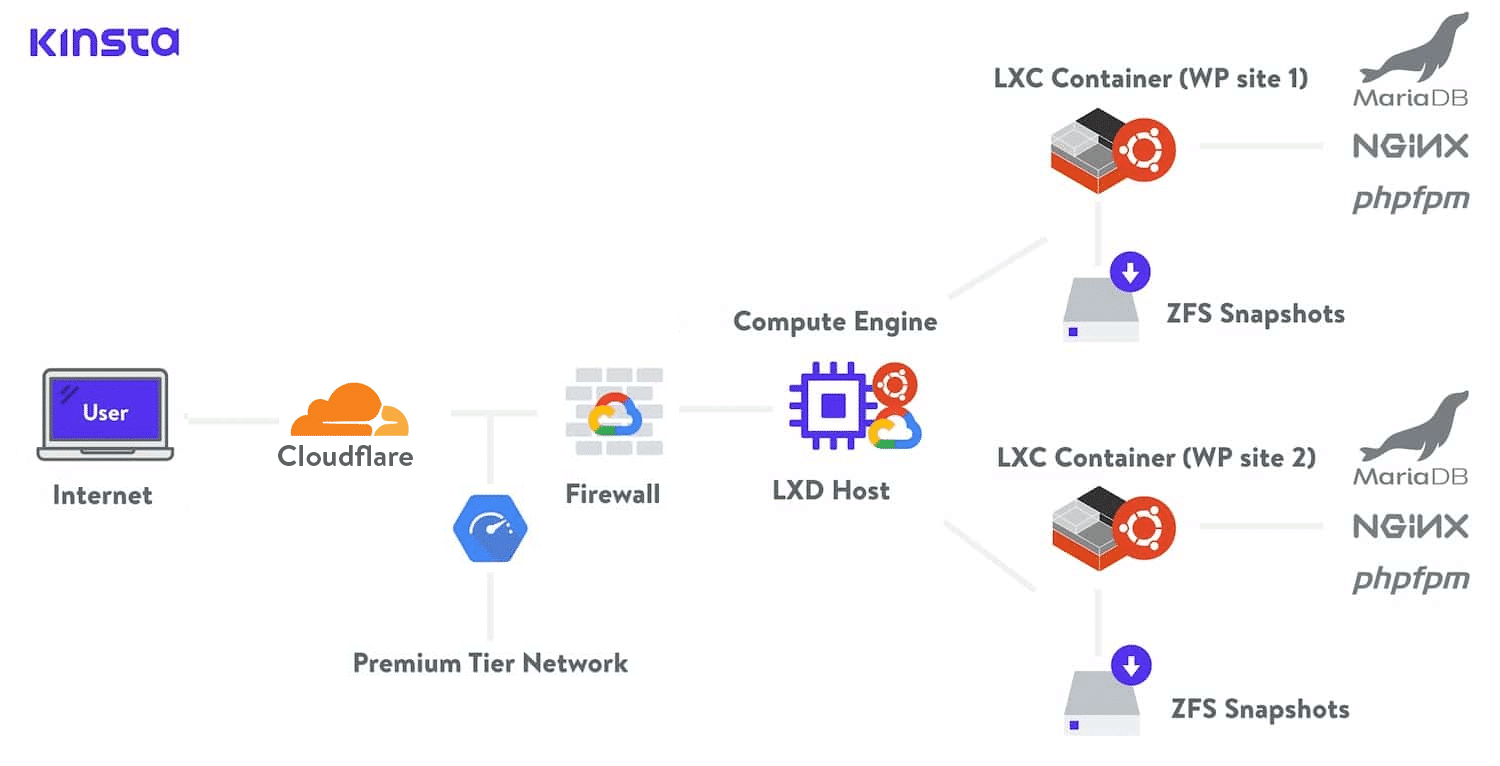
Red de Niveles Estándar de Google
Por otro lado, la Red de Nivel Estándar utiliza Puntos de Presencia cerca del centro de datos donde reside nuestro contenido o aplicación web. Esto significa que el tráfico de nuestros visitantes viajará a través de diferentes redes, sistemas autónomos, ISPs, y a través de muchos saltos hasta llegar a su destino. En este escenario, la velocidad se ve comprometida.
El contenido que viaja en el nivel estándar no podrá cosechar completamente los beneficios de la SDN de Google y de la gran potencia de cálculo para calcular las mejores rutas de forma dinámica. El tráfico estará sujeto a las políticas BGP de todos los sistemas entre Google y el visitante.
Para decirlo en términos simples. Los paquetes de nivel estándar pasan menos tiempo en la red de Google, y más tiempo jugando a la patata caliente en las redes públicas, y por lo tanto, se desempeñan peor (pero cuestan menos).
Además, Premium Tier utiliza el Balanceo de Carga Global, mientras que el Tier Standard ofrece sólo el Balanceo de Carga Regional, lo que trae más complejidad, y más «trabajo de base» para los clientes en el Standard.
La Red de Niveles Premium ofrece un Acuerdo de Nivel de Servicio (SLA) global, lo que significa que Google acepta la responsabilidad contractual de ofrecer un determinado nivel de servicio. Es como una señal de garantía de calidad. Los niveles de red estándar no ofrecen este nivel de SLA.
Para aquellos que quieran saber más, hay una comparación y documentación bastante extensa de los dos niveles en el sitio web de Google Cloud. Incluso proporcionan un gráfico práctico para ayudarle a determinar más fácilmente qué nivel de red debe utilizar:

Resumen
Durante años, Google ha invertido en la creación de una infraestructura de red global, desplegando sus propios protocolos y pilas de redes de hardware y software personalizadas. En tiempos en los que la ley de Moore parece debilitarse año tras año, la infraestructura de Google permite a la empresa mantenerse al día con la creciente demanda de recursos de la nube.
Aunque en términos de cuota de mercado sigue estando por detrás de Amazon Cloud y Azure Cloud de Microsoft, Google ha obtenido una ventaja crucial tanto por la fibra que posee como por las soluciones de hardware y software de última generación que han implementado sus ingenieros.
Podemos esperar que Google desempeñe un papel clave en la tecnología de la IO, las ciudades inteligentes, los coches sin conductor, y la demanda de edge computing sigue creciendo.
Google Cloud Network Premium Tier es el primer producto que utiliza los innovadores logros de red de Google. Permite a los clientes aprovechar la red de Google y toda la pila para entregar contenido a una velocidad superior. Con las garantías de Google en cuanto a la latencia.
Kinsta se dedica a proporcionar el mejor Alojamiento de Aplicaciones, Alojamiento de Bases de Datos y Alojamiento Administrado de WordPress a escala global. Por eso, Kinsta se impulsa con el alojamiento en la nube de Google y utilizamos la Red de Nivel Premium de Google para todos nuestros planes de alojamiento.



Deja una respuesta