
Nella corsa odierna per accelerare i tempi di caricamento dei siti web, ogni millisecondo è importante. Il team di Kinsta ha testato e analizzato l’impatto della velocità dei siti web su vendite, conversioni, esperienza utente e coinvolgimento degli utenti.
Ma c’è un avvertimento. Sebbene l’ottimizzazione del sito è importante per migliorare la velocità, non è l’unico aspetto da considerare. Le infrastrutture hardware e di rete che supportano il nostro sito web e lo collegano ai nostri visitatori sono importanti.
Oggi discuteremo dei motivi per cui Google sta investendo un sacco di soldi nell’infrastruttura di rete e analizzeremo alcune delle differenze tra rete di livello premium e rete di livello standard di Google Cloud Platform.
Larghezza di Banda e Latenza (Criteri Chiave per le Prestazioni dell’Infrastruttura di Hosting)
Prima di approfondire le specifiche del network di Google Cloud, è importante comprendere innanzitutto questi due concetti: larghezza di banda e latenza.
La larghezza di banda è la capacità di portata della rete, misurata in Mbps; mentre la latenza è il ritardo o la somma di tutti i ritardi che i diversi router aggiungono lungo il percorso alle nostre richieste e risposte web.
In senso figurato, la larghezza di banda o la portata possono essere rappresentate come capacità del tubo dell’acqua per consentire un determinato volume di acqua al secondo. La latenza può essere paragonata al ritardo dal momento in cui la tubatura dell’acqua viene aperta fino a quando non inizia a uscire.
A causa della breve attesa nello stabilire la connessione tra diversi router, ogni “salto” lungo il percorso aggiunge latenza alle richieste e alle risposte finali.
Quindi, più lontani sono il visitatore e il server su cui è ospitato il sito, maggiore sarà la latenza. Inoltre, più la rete è frammentata, maggiore è la latenza.
Possiamo immaginarlo usando uno strumento chiamato traceroute, o tracert su windows. Lo abbiamo utilizzato per ispezionare i ritardi di instradamento di due richieste, fatte dall’Europa, i cui dati sono visualizzati negli screenshot che seguono. In particolare:
uno su weibo.com:

e un altro su bbc.co.uk:

Come ci aspettavamo, il numero di salti verso il sito web in Cina è quasi 2 volte maggiore rispetto a quello europeo. È latenza aggiunta rispetto a una richiesta verso un sito web ospitato nel Regno Unito.
Le tre colonne mostrate da tracert rappresentano tre roundtrip (RTT). Ogni riga rappresenta router o hop diversi lungo il percorso. Spesso questi strumenti forniscono URL che aiutano a determinare dove si trova quel router specifico.
Il tempo di andata e ritorno (round-trip) per i router in Cina / Hong Kong dura quasi un terzo di secondo.
Abbiamo utilizzato gli strumenti di pingdom per caricare un sito web ospitato a Londra dalla location in Australia di Pingdom, per cercare di stabilire la parte di responsabilità che la rete ha nei tempi di caricamento complessivi di un sito web.

Questi sono i dati per un piccolo file CSS caricato in questo scenario di prova. La sezione Connect ha la parte maggiore nel caricamento di questa risorsa, seguita da SSL e Wait. Tutto il tempo fino a, incluso il tempo di attesa (Wait time), insieme, è anche noto come time to first byte (TTFB), che comprende la latenza di rete.
Quando gli Internet Service Provider pubblicizzano la velocità della connessione Internet, di solito pubblicizzano sulla loro larghezza di banda (la “larghezza del tubo” ricordate?), che in realtà non è una misura della velocità. L’aumento della larghezza del tubo può aumentare la velocità del sito solo fino a un certo punto. È più utile quando abbiamo bisogno di una grande quantità di dati inviati per secondo, come quando trasmettiamo in streaming contenuti video ad alta definizione. Ma per gli utenti che potrebbero giocare online a partite multiplayer in tempo reale, la latenza conta molto di più.
Mike Belshe, uno dei coautori della specifica di HTTP/2 e del protocollo SPDY, ha fatto un’analisi dell’impatto di una maggiore larghezza di banda sulla velocità di caricamento di un sito web rispetto all’effetto della diminuzione della latenza sulla velocità di caricamento.
Ecco i risultati di Belshe curati in un bel grafico:

Dovrebbe essere chiaro che aumentare la velocità del sito aumentando la larghezza di banda non è il modo più efficace per ottenere prestazioni migliori. D’altra parte, riducendo l’RTT (round-trip-time) o la latenza, possiamo registrare miglioramenti consistenti del tempo di caricamento della pagina.
Networks vs Internet Peering vs Transit
Per capire meglio il nostro argomento, dobbiamo partire dalle basi della topologia di Internet. Alla suo core, l’Internet globale è costituito da più reti globali, regionali e locali.
A partire dal 2018, ci sono oltre 60.000 AS (Sistemi Autonomi). Queste reti appartengono a governi, università, ISP.
Tra questi, distinguiamo le reti Tier 1, Tier 2 e Tier 3. Questi livelli rappresentano l’indipendenza di ciascuna rete su Internet nel suo insieme.
- Le reti di livello 1 (Tier 1) sono indipendenti, nel senso che non devono pagare per connettersi a qualsiasi altro punto su Internet.
- Le reti di livello 2 (Tier 2) hanno accordi di peering con altri ISP, ma pagano anche per il transito.
- Le reti di livello 3 (Tier 3), il livello più basso, si collegano al resto di Internet acquistando il transito da livelli superiori. Sono praticamente come i consumatori che devono pagare per accedere a Internet.
Relazione di peering significa che due reti si scambiano traffico su una base egualitaria, in modo che nessuna delle due paghi l’altra per il transito.
Il vantaggio principale del peering è una latenza drasticamente inferiore.

Nell’immagine qui sopra, vediamo uno scenario classico, in cui la richiesta passa attraverso la rete gerarchica di ISP di livello 1, livello 2 e livello 3 al fine di recuperare un sito web ospitato in un data center in una località remota.
Le frecce rappresentano il percorso della richiesta web. Le frecce tratteggiate rappresentano le connessioni di transito e le frecce a linea intera rappresentano le connessioni di peering.
Una volta raggiunto il provider di livello 1, la sua relazione con un altro provider sullo stesso livello è una relazione alla pari. Le reti di livello 1 si collegano ad altre e inoltrano le loro richieste esclusivamente attraverso partner di pari livello. Possono raggiungere tutte le altre reti su Internet senza pagare per il transito.
Possiamo anche vedere uno scenario alternativo, in cui due fornitori di livello 2 hanno un accordo di peering, designato con il colore turchese. Il numero di salti in questo scenario è inferiore e il caricamento del sito richiederà molto meno tempo.
Border Gateway Protocol
BGP è un protocollo di cui si parla raramente, tranne che in contesti molto tecnici. Tuttavia, questo protocollo è al centro della Internet come la conosciamo oggi. È fondamentale per la nostra capacità di accedere a quasi tutto su Internet ed è uno dei collegamenti vulnerabili nello stack del protocollo Internet.
Il protocollo Border Gateway è definito nella Request For Comments IETF #4271 del 2006 e da allora è stato aggiornato diverse volte. Come dice la RFC:
“La funzione principale di un sistema parlante BGP è lo scambio di informazioni sulla raggiungibilità della rete con altri sistemi BGP.”
Per dirla con parole semplici, BGP è un protocollo responsabile per decidere il percorso esatto di una richiesta di rete, su centinaia o migliaia di possibili nodi verso la sua destinazione.

Possiamo immaginare ogni nodo come un sistema autonomo o un network che potrebbe consistere di più nodi o router, server e sistemi ad esso collegati.
Nel protocollo BGP, non esiste un algoritmo di individuazione automatica (un meccanismo o protocollo attraverso il quale ogni nodo appena connesso può scoprire nodi adiacenti cui connettersi). Invece bisogna specificare manualmente i peer di ogni peer BGP. Per quanto riguarda l’algoritmo del percorso, per citare un esperto Cisco:
“BGP non ha una metrica semplice per decidere il percorso migliore. Invece, con ogni percorso rende pubblico un ampio set di attributi e utilizza un algoritmo complesso composto da un massimo di 13 passaggi per decidere quale sia il percorso migliore.”
I sistemi autonomi trasmettono i dati di routing ai loro peer, tuttavia non esistono regole rigide da poter applicate per quanto riguarda la selezione del percorso. BGP è un sistema implicitamente basato sulla fiducia e questo potrebbe essere uno dei maggiori difetti per la sicurezza di Internet oggi. Furto nel 2018, quando il traffico di MyEtherWallet.com è stato dirottato e più di 200 Ether sono stati rubati (valore di $152.000) e hanno esposto questa vulnerabilità.
In realtà, questa debolezza di BGP fa spesso sì che diverse reti (AS) emettano dati BGP tenendo conto di interessi diversi dall’efficienza e dalla velocità per gli utenti finali. Possono essere interessi commerciali, come il transito a pagamento, o anche considerazioni politiche o di sicurezza.
Sviluppo di Cloud Computing, CDN e Edge Market
Date le crescenti esigenze del mercato IT, dall’industria del Web ai giochi online, all’Internet of Things e ad altri ambiti, lo spazio di mercato per fornitori di servizi e prodotti che risolvono il problema della latenza è diventato evidente.
Anno dopo anno, vediamo sempre più prodotti basati sul cloud che memorizzano nella cache risorse statiche vicino ai visitatori (Content Delivery Network) o avvicinano il calcolo reale agli utenti finali. Uno di questi prodotti è Cloudflare’s Workers, che esegue il codice compatibile con il motore javascript V8 sul network di “edge node” di Cloudflare. Ciò significa che anche il codice WebAssembly o GO possono essere eseguiti molto vicino al visitatore.
[email protected] di Amazon è un altro esempio di questa tendenza, così come la partnership tra Intel e Alibaba Cloud per fornire la Joint Edge Computing Platform destinata al mercato IoT.
Un altro esempio degno di nota è il network globale di Google dei nodi di cache che ha la funzione sia di CDN sia di rete di cache e rete di distribuzione per la sua controllata YouTube.
Per illustrare quanto sia diventata raffinata e avanzata l’industria del cloud e quanto sia riuscita a ridurre la latenza della rete per gli utenti finali, diamo un’occhiata a GaaS.
GaaS è l’abbreviazione di Gaming as a Service. È un’offerta cloud che offre agli utenti la possibilità di giocare ai giochi ospitati ed eseguiti nel cloud. Questo articolo mette a confronto alcuni prodotti di spicco nella nicchia GaaS.
Chiunque abbia mai fatto acquisti per una TV o un videoproiettore per i giochi, o abbia trascorso un po’ di tempo a configurare Miracast o un’altra connessione di trasmissione tra una TV e un altro dispositivo, saprà quanto sia importante la latenza. Eppure, ci sono fornitori di GaaS che ora offrono game streaming con risoluzione 4k e frequenza di aggiornamento di 60Hz… e i giocatori non devono investire in hardware.
Il dramma della recente esclusione di Huawei da parte degli Stati Uniti ha portato all’attenzione il problema delle reti 5G e l’urgente necessità di un percorso chiaro per aggiornare l’infrastruttura di rete del mondo.
I sensori che trasmettono enormi quantità di informazioni in tempo reale, con una latenza minima, per coordinare smart city, smart house, veicoli autonomi dipenderanno da fitte reti di dispositivi periferici. La latenza è il limite attuale per cose come le auto a guida autonoma, con diverse informazioni sui sensori, dati LIDAR, elaborazione di questi dati rispetto ai dati di altri veicoli.
Le reti di distribuzione dei contenuti e i fornitori di cloud computing sono in prima linea in questa gara. Abbiamo già parlato del protocollo QUIC / HTTP3 implementato dai leader del settore in grado di controllare il ciclo richiesta-risposta.
Come i Provider Cloud Risolvono il Problema della Latenza?
AWS potrebbe essere il maggiore fornitore di cloud in base alla quota di mercato. Nel 2016, hanno investito nel Hawaiki Transpacific Submarine Cable System con l’obiettivo di fornire una maggiore larghezza di banda e ridurre la latenza tra Hawaii, Australia e Nuova Zelanda, ed è stato il loro primo investimento in infrastrutture sottomarine. È entrato in funzione nel 2018.

A quel tempo, Google era già molto avanti rispetto alla concorrenza nel disporre le dorsali sottomarine. Un anno prima del primo investimento di Amazon, ITWorld pubblicò un articolo dal titolo: “I data center di Google crescono troppo velocemente per le reti normali, quindi costruiscono le proprie”.
In effetti, è stato nel 2005 che il giornalista di tecnoclogia Mark Stephens, alias Robert X Cringely, ha scritto nella sua rubrica per PBS.org, commentando la follia commerciale di Google sulla dark fiber (infrastruttura in fibra ottica strutturata ma inutilizzata):
“È più di un altro Akamai o anche un Akamai sotto steroidi. Si tratta di un Akamai termonucleare intelligente, guidato dinamicamente, con un back-channel dedicato e hardware application-specific. Ci sarà Internet, e poi ci sarà Internet di Google, collocata al top.”

Nel 2010, in un articolo su zdnet.com, Tom Foremski affermava:
“Google è una di quelle aziende che possiedono una grande fetta di Internet” e continua: “Google si è concentrata sulla costruzione della più efficiente e più economico Internet privata. Questa infrastruttura è la chiave di Google ed è la chiave per comprendere Google “.
A quel tempo, l’articolo di Cringley sollevava alcune preoccupazioni sul fatto che Google cercasse di impadronirsi di Internet, ma le cose si sono chiarite quando la società ha lanciato Google Fiber, il tentativo di Google di conquistare il mercato ISP nelle maggiori città degli Stati Uniti. Da allora il progetto ha subito un rallentamento, tanto che TechRepublic pubblicò un post-mortem del progetto nel 2016, ma gli investimenti nell’infrastruttura, ora su scala globale, non hanno rallentato.
L’ultimo investimento di Google, destinato a diventare operativo quest’anno, è una dorsale che collega Los Angeles negli Stati Uniti e Valparaiso in Cile, con una ramificazione per il futuro collegamento con Panama.
“Internet è normalmente descritto come un cloud. In realtà, è una serie di tubi bagnati e fragili e Google sta per possederne un numero allarmante.” — VentureBeat
Perché Google Sta Investendo Tanto Nella Sua Infrastruttura di Rete?

Sappiamo tutti che Google è il motore di ricerca numero uno, ma anche che:
- Possiede la più grande piattaforma video
- È il più grande provider di posta elettronica (Gmail e Google Workspace)
- Guadagna un bel po’ di soldi con i suoi prodotti di cloud computing (tasso annuale di oltre $ 8 miliardi di dollari)
Ecco perché ha bisogno della minima latenza possibile e della massima larghezza di banda possibile. Google vuole anche possedere l’infrastruttura reale, perché la sua “fame insaziabile” di maggiore larghezza di banda e latenza mette Google, e le aziende sue pari di grandi dimensioni come Amazon o Microsoft, in una posizione in cui devono trovare soluzioni hardware e software completamente personalizzate.

I Points of Presence, o nodi PoP periferici, sono ai margini della rete via cavo privata globale di Google. Lì servono come punti di entrata e di uscita per il traffico che si collega ai data center di Google.
La legge di Moore nasce da un’osservazione di Gordon Moore, co-fondatore di Intel, che affermava che ogni due anni il numero di transistor che possiamo mettere su un circuito integrato raddoppia. Per decenni, questa aspettativa è rimasta vera, ma ora l’industria informatica sta per mettere la legge di Moore a dura prova, e potrebbe forse segnare la sua fine in un futuro vicino. Per vostra informazione, il CEO di NVIDIA ha dichiarato la legge di Moore morta all’inizio di quest’anno.
In che modo questo si collega al settore del cloud e all’infrastruttura di rete di Google?
All’evento Open Networking Foundation Connect del dicembre del 2018, Amin Vahdat, vicepresidente di Google e TechLead for Networking, ha ammesso la fine della legge di Moore e ha svelato l’enigma dell’azienda:
“Le nostre necessità di calcolo stanno continuando a crescere a un ritmo sorprendente. Avremo bisogno di acceleratori e di calcoli abbinati più strettamente. La struttura della rete svolgerà un ruolo fondamentale nel collegare questi due elementi.”
Un modo per i provider di cloud di tenere il passo con la crescente domanda di potenza di calcolo è il clustering. Clustering, per dirla con parole semplici, significa mettere insieme più computer per lavorare su un singolo problema, per eseguire processi di una singola applicazione. Ovviamente, una condizione preliminare per beneficiare di tale configurazione è la bassa latenza o la seria capacità della rete.
Quando Google iniziò a progettare il proprio hardware, nel 2004, i fornitori di hardware di rete pensavano in termini di scatole e i router e gli switch dovevano essere gestiti individualmente, tramite riga di comando. Fino ad allora, Google stava acquistando gruppi di switch da fornitori come Cisco, spendendo una fortuna per singolo switch. Ma l’attrezzatura non è ancora riuscita a tenere il passo con la crescita.
Google aveva bisogno di una diversa architettura di rete. La domanda sull’infrastruttura di Google stava crescendo in modo esponenziale (un documento di ricerca di Google del 2015 afferma che la loro capacità di rete era cresciuta di 100 volte in dieci anni) e la loro crescita è stata così rapida che il costo di acquisto dell’hardware esistente li ha spinti anche a creare proprie soluzioni. Google ha iniziato a costruire switch personalizzati a partire da chip al silicio, adottando una diversa topologia di rete, che era più modulare.
Gli ingegneri di Google hanno iniziato a basarsi su un vecchio modello di rete di telefonia chiamato Clos Network, che riduce il numero di porte richieste per switch:
“Il vantaggio della Clos Network è che è possibile utilizzare una serie di dispositivi identici ed economici per creare l’albero e ottenere elevate prestazioni e resilienza che altrimenti sarebbero più costosi da costruire.” — Clos Networks: What’s Old Is New Again, Network World
Per questo nuovo hardware modulare, il team di Google ha dovuto anche ridefinire i protocolli esistenti e creare un sistema operativo di rete personalizzato. La sfida che stavano affrontando era quella di prendere un gran numero di switch e router e farli funzionare come se fossero un unico sistema.
Lo stack di rete personalizzato, con la necessità di protocolli ridefiniti, ha portato Google a passare al Software Defined Networking (SDN). Ecco un keynote del 2015 di Amin Vahdat, Vicepresidente di Google, Engineering Fellow e responsabile del team delle infrastrutture di rete, che spiega tutte le sfide affrontate e le soluzioni che hanno proposto:
Per i più curiosi, c’è questo interessante post che vale la pena leggere.
Espresso
Espresso è l’ultimo pilastro dell’SDN di Google. Consente alla rete di Google di andare oltre i vincoli dei router fisici nell’apprendimento e nel coordinamento del traffico in entrata e in uscita verso i partner di peering di Google.
Espresso consente a Google di misurare le prestazioni delle connessioni in tempo reale e di basare la decisione sul miglior Point of Presence per un visitatore specifico su dati in tempo reale. In questo modo, la rete di Google può rispondere in modo dinamico a diverse congestioni, rallentamenti o interruzioni nei suoi partner di peering / ISP.
Su tutto questo, Espresso consente di utilizzare la potenza di calcolo distribuito di Google per analizzare tutti i dati di rete dei suoi peer. Tutto il controllo e la logica del routing non risiedono più con i singoli router e il protocollo Border Gateway ma vengono invece trasferiti sulla rete informatica di Google.
“Sfruttiamo la nostra infrastruttura di elaborazione su larga scala e i segnali dall’applicazione stessa per conoscere le prestazioni dei singoli flussi, in base alla percezione della qualità dell’utente finale.” — Espresso rende più veloce Google Cloud, 2017
In che Modo Ognuno di Questi Aspetti è Rilevante per Google Cloud Network?
Ciò che abbiamo trattato finora evidenzia tutti i problemi e le sfide (sia hardware che software) che Google ha affrontato per assemblare quella che è probabilmente la migliore rete privata globale oggi disponibile.
Per quel che riguarda le quote di mercato, Google Cloud Platform è il terzo fornitore globale (dopo AWS e Microsoft quota di mercato di Azure). Ma in termini di infrastruttura di rete privata premium, lascia molto indietro i suoi concorrenti, come mostrano questi dati di BroadBand Now:

Nel 2014, GigaOM pubblicò un articolo che confrontava AWS e Google Cloud Platform, ma solo una settimana dopo ne ha pubblicato un altro intitolato: “Quello che mi sono perso nel dibattito tra Google e Amazon Cloud – fibra!”, in cui riconoscono che Google è avanti di anni in termini di infrastruttura.
“Avere cavi grandi e veloci a disposizione per te – e per il traffico dei tuoi clienti – è una grande sfida.” – Barb Darrow, GIGAOM
Confronto tra Premium Tier e Standard Tier di Google Network

Google Cloud Platform offre due diversi livelli di rete che differiscono sia per il prezzo che per le prestazioni.
Premium Tier Network di Google
Con la Premium Tier Network di Google, gli utenti possono sfruttare la rete in fibra globale, con Points of Presence distribuiti a livello globale. Tutto il traffico in ingresso (in entrata) dal cliente ai data center di Google viene instradato al Points of Presence più vicino. Questi sono distribuiti a livello globale, quindi la richiesta viene instradata al 100% sulla dorsale privata di Google. Come accennato in un precedente articolo, ciò può significare una latenza migliorata del 30% o una larghezza di banda migliore del 50%.
Sulla via del ritorno, tutti i dati inviati dal data center al visitatore vengono instradati utilizzando la policy Cold Potato. A differenza del routing Hot Potato, utilizzato sulla rete di livello standard, in cui il traffico viene, il più presto possibile, consegnato (o eliminato) verso altri ISP, il routing di livello Premium fa sì che il traffico in uscita viene mantenuto il più possibile sulla fibra di Google, e viene consegnato a peer o agli ISP di transito il più vicino possibile al visitatore.
Diciamolo in parole povere. I pacchetti di livello Premium trascorrono più tempo sulla rete di Google, con meno rimbalzi e quindi prestazioni migliori (ma costano di più).
Per i fan della fantascienza, potrebbe essere paragonato a un wormhole cosmico, che trasferisce il nostro traffico direttamente alla nostra destinazione senza il roaming attraverso Internet.
Da Kinsta utilizziamo la rete Premium Tier di Google Cloud in tutti i nostri piani di hosting. Ciò riduce al minimo distanza e salti, garantendo un trasporto globale più rapido e sicuro dei dati.
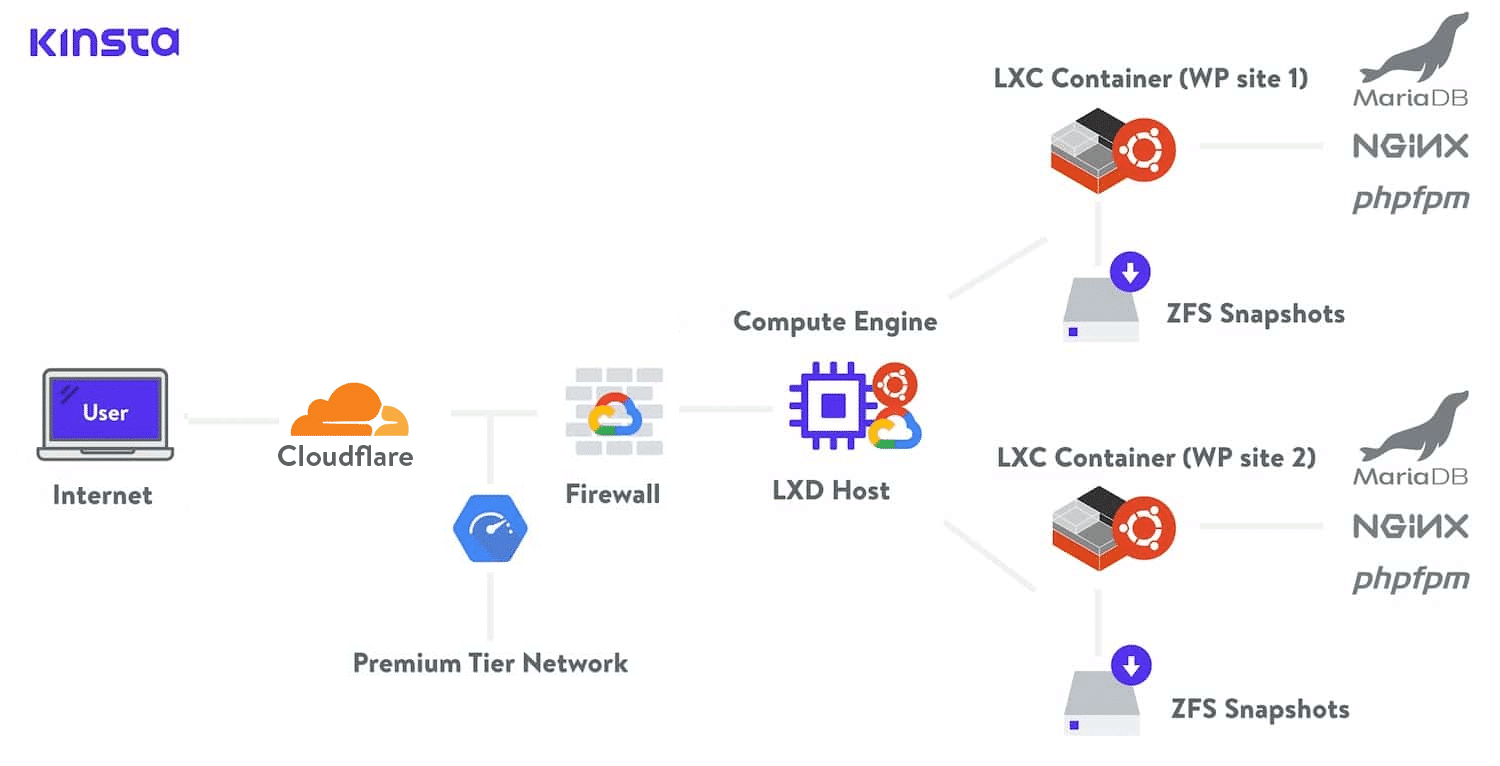
Standard Tier Network di Google
D’altra parte, la rete di livello standard utilizza i punti di presenza vicino al data center in cui risiedono i nostri contenuti o web app. Ciò significa che il traffico dei nostri visitatori viaggerà attraverso diverse reti, sistemi autonomi, ISP e subirà molti salti fino a raggiungere la sua destinazione. In questo scenario, la velocità è compromessa.
I contenuti che viaggiano su un livello standard non saranno in grado di sfruttare appieno i vantaggi della SDN di Google e la grande potenza di elaborazione necessaria per calcolare dinamicamente i percorsi migliori. Il traffico sarà soggetto alle policy BGP di tutti i sistemi tra Google e il visitatore.
Diciamolo con parole semplici. I pacchetti di livello standard trascorrono meno tempo sulla rete di Google e più tempo a giocare a hot potato sulle reti pubbliche e, quindi, ottengono risultati peggiori (ma costano meno).
In aggiunta, il livello Premium utilizza il Global Load Balancing, mentre il livello standard offre solo il Regional Load Balancing, il che porta maggiore complessità e più “footwork” per i clienti sul livello Standard.
Il Premium Tier Network offre un Service Level Agreement (SLA) globale, il che significa che Google si assume la responsabilità contrattuale di fornire un determinato livello di servizio. È una garanzia di qualità. I livelli di rete standard non offrono questo livello di SLA.
Per chi desidera saperne di più, esiste un confronto e una documentazione piuttosto ampi dei due livelli sul sito web di Google Cloud. C’è anche una tabella utile per aiutarvi a determinare più facilmente quale livello di rete scegliere:

Riepilogo
Per anni, Google ha investito nella creazione di un’infrastruttura di rete globale, implementando i propri protocolli e stack di rete hardware e software personalizzati. In tempi in cui la legge di Moore sembra indebolirsi anno dopo anno, l’infrastruttura di Google consente all’azienda di tenere il passo con la domanda sempre crescente di risorse cloud.
Sebbene in termini di quota di mercato sia ancora dietro Amazon Cloud e Azure Cloud di Microsoft, Google si è guadagnato alcuni vantaggi cruciali sia per la fibra che possiede, sia per le soluzioni hardware e software all’avanguardia implementate dai suoi ingegneri.
Possiamo aspettarci che Google svolga un ruolo chiave nella tecnologia di IoT, città intelligenti, auto a guida autonoma e che la domanda di edge computing continui a crescere.
Il livello Premium di Google Cloud Network è il primo prodotto a utilizzare le innovative conquiste di networking di Google. Consente ai clienti di sfruttare la rete di Google e l’intero stack per fornire contenuti a velocità premium. Con le garanzie di Google per quanto riguarda la latenza.
Kinsta si impegna a fornire le migliori prestazioni per l’Hosting di Applicazioni, l’Hosting di Database e l’Hosting WordPress Gestito su scala globale. Per questo motivo Kinsta si avvale dell’hosting Google Cloud e della rete Premium Tier di Google per tutti i nostri piani di hosting.



Lascia un commento